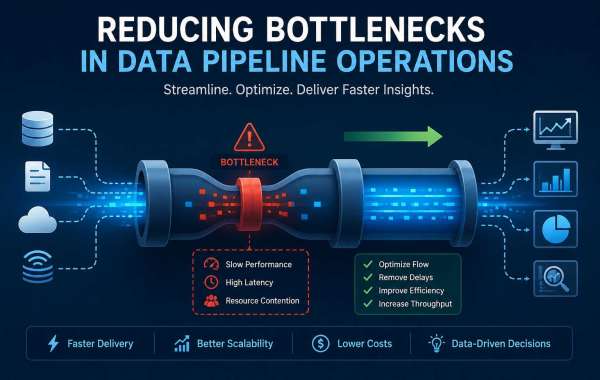
Modern organizations rely heavily on data to make informed decisions, improve customer experiences, and drive business growth. Data pipelines play a critical role in moving information from multiple sources to storage systems, analytics platforms, and reporting tools. However, as data volumes increase and business requirements become more complex, pipelines can experience bottlenecks that slow down processing and reduce efficiency.
Companies such as Extract Mails understand the importance of maintaining smooth and reliable data workflows. When bottlenecks occur, they can delay critical insights, increase operational costs, and negatively impact productivity. Understanding the causes of these issues and implementing effective solutions is essential for ensuring consistent pipeline performance.
Understanding Data Pipeline Bottlenecks
A data pipeline bottleneck occurs when one stage of the pipeline cannot process data as quickly as it is received. This creates a backlog that slows the entire workflow. Bottlenecks can appear in data ingestion, transformation, storage, processing, or delivery stages.
As organizations collect larger amounts of data from different sources, even small inefficiencies can grow into significant performance challenges. Identifying these constraints early helps prevent delays and ensures that data remains accessible when needed.
Common Causes of Pipeline Bottlenecks
Increasing Data Volume
One of the most common reasons for pipeline slowdowns is rapid data growth. Systems that once handled moderate workloads may struggle when data volumes increase significantly.
As businesses expand, customer interactions, application logs, transaction records, and other datasets continue to grow. Without proper scaling strategies, pipeline components may become overwhelmed, leading to slower processing times.
Inefficient Data Transformations
Data transformation is often one of the most resource-intensive stages in a pipeline. Complex calculations, unnecessary processing steps, and poorly optimized queries can consume valuable computing resources.
Organizations often focus on adding new features and transformations without regularly reviewing performance. Over time, these processes become increasingly difficult to manage and can significantly reduce pipeline efficiency.
Limited Infrastructure Resources
Pipelines depend on computing power, memory, storage, and network bandwidth. When infrastructure resources are insufficient, processing delays become inevitable.
Resource limitations are especially noticeable during peak usage periods when multiple systems compete for the same infrastructure. Without adequate capacity planning, performance issues can quickly escalate.
Poor Data Quality
Data quality problems can create hidden bottlenecks throughout the pipeline. Missing values, duplicate records, inconsistent formats, and invalid entries often require additional processing before data can be used.
When data cleansing tasks become excessive, pipeline performance suffers. Maintaining high-quality data at the source helps reduce unnecessary processing and improves overall efficiency.
The Importance of Performance Monitoring
Monitoring is one of the most effective ways to identify and resolve bottlenecks. Without visibility into pipeline performance, organizations may struggle to determine where delays are occurring.
Real-time monitoring provides valuable insights into processing speeds, resource utilization, data throughput, and system health. By tracking key performance indicators, teams can quickly detect anomalies and take corrective action before small issues become major problems.
Regular performance reviews also help organizations understand long-term trends and prepare for future growth.
Strategies for Reducing Bottlenecks
Optimize Data Processing Workflows
Improving workflow design is often the first step toward reducing bottlenecks. Organizations should evaluate each stage of the pipeline and remove unnecessary processing tasks.
Simplifying transformations, reducing redundant operations, and streamlining data movement can significantly improve performance. Small adjustments often produce substantial gains in efficiency.
Implementing effective etl process optimization can further enhance workflow performance by reducing resource consumption and improving data processing speed.
Use Parallel Processing
Parallel processing allows multiple tasks to run simultaneously instead of sequentially. This approach can dramatically increase throughput and reduce processing delays.
Rather than waiting for one operation to finish before starting another, workloads are distributed across multiple computing resources. This improves scalability and helps pipelines handle larger datasets more effectively.
Scale Infrastructure Strategically
Scaling infrastructure is essential for supporting growing data demands. Organizations should adopt flexible systems that can expand as workloads increase.
Cloud-based platforms provide scalable resources that can be adjusted based on demand. This flexibility helps maintain performance while controlling operational costs.
Strategic scaling ensures that resources are available when needed without unnecessary overprovisioning.
Improve Database Performance
Databases often become a major source of pipeline bottlenecks. Slow queries, poor indexing, and inefficient storage structures can significantly impact performance.
Organizations should regularly review database configurations and optimize query execution. Proper indexing and partitioning strategies can reduce retrieval times and improve overall pipeline efficiency.
Database maintenance should be treated as an ongoing process rather than a one-time task.
Enhancing Data Ingestion Efficiency
Streamline Data Collection
Data ingestion serves as the entry point for the entire pipeline. Inefficiencies at this stage can affect every downstream process.
Organizations should minimize unnecessary data transfers and ensure that only relevant information enters the pipeline. Reducing redundant data collection helps conserve resources and improve processing speed.
Implement Incremental Processing
Processing only newly added or modified data can significantly reduce workloads. Instead of reprocessing entire datasets repeatedly, incremental approaches focus on changes since the last execution.
This method decreases processing time, lowers resource consumption, and improves pipeline responsiveness.
The Role of Automation
Automation plays a crucial role in maintaining efficient pipeline operations. Manual monitoring and intervention become increasingly difficult as systems grow more complex.
Automated workflows can detect performance issues, allocate resources, trigger alerts, and execute corrective actions without human involvement. This reduces operational overhead while improving reliability.
Automation also helps maintain consistency across environments and minimizes the risk of human error.
Building a Scalable Pipeline Architecture
Scalability should be considered from the beginning of pipeline design. Many bottlenecks occur because systems were built to handle current needs rather than future growth.
A scalable architecture incorporates modular components that can be expanded independently. This approach allows organizations to upgrade specific pipeline sections without redesigning the entire system.
Key characteristics of scalable pipelines include:
- Flexible resource allocation
- Distributed processing capabilities
- Fault-tolerant design
- Efficient storage management
- Real-time monitoring integration
By designing for scalability, organizations can better adapt to changing business requirements and increasing data volumes.
Maintaining Long-Term Performance
Reducing bottlenecks is not a one-time project. Data environments continuously evolve, creating new challenges and opportunities for improvement.
Regular audits, performance testing, and capacity planning help ensure that pipelines continue operating efficiently. Organizations should establish ongoing review processes to identify emerging issues before they impact operations.
Continuous improvement efforts contribute to better reliability, lower costs, and faster access to critical business insights.
Conclusion
Data pipelines are essential for modern business operations, but bottlenecks can limit their effectiveness if left unaddressed. From growing data volumes and inefficient transformations to infrastructure limitations and data quality issues, multiple factors can contribute to performance slowdowns.
Organizations that prioritize monitoring, automation, scalable architecture, and workflow optimization are better positioned to maintain efficient and reliable pipelines. By taking a proactive approach to performance management, businesses can reduce delays, improve resource utilization, and ensure that valuable data reaches decision-makers when it matters most.
For organizations seeking stronger data operations and long-term efficiency, focusing on Pipeline Bottleneck Reduction can provide a solid foundation for scalable and high-performing data workflows.




